NEW GAME!を観ました。プログラミング始めます。(23)
失踪じゃないです。ちょっと休んでただけです。

※基本的に、愛知大学の有澤先生がプログラミングの講義で使用しているテキスト「Pythonによるプログラミング入門」に沿って進めています。
※Python 2.7.13を使用しています。
今回のテーマは「置き石ゲーム」です。難易度跳ね上がってます。
置き石ゲーム
1. ゲームのルール
テキストでの置き石ゲームは、5×5のマス目に2人が交互に石を置き、自分のターンに石を置くことができなければ負けというものです。ただし、それぞれの石は隣り合って置くことができません。
例えば以下のようになります。
(引用元:Pythonによるプログラミング入門, p. 54)
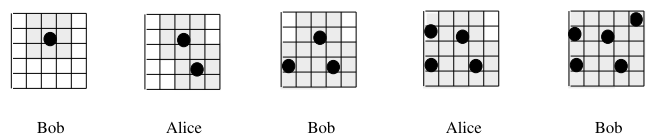
この場合、Alice は次に石を置くことができず、負けになります。
2. プログラムの考え方
ここでは、置き石ゲームに勝つためのプログラムを考えます。
早速ですが、プログラムの全貌を見てみましょう。
譜 4.14 置き石ゲームの次の手を見つけるプログラム
from copy import * def put(d,p): for i in -1,0,1: for j in -1,0,1: q=(p[0]+i,p[1]+j) if d.count(q): d.remove(q) def pr(d): for p in d: print p, print def next(d): if len(d)==0: return None # No space to put a stone. I've lost. pr(d) for p in d: print p,":", e=copy(d) # make a copy of d to protect from modification. put(e,p) # put a stone if next(e)==None: # and glance at Frank return p # he looks pale. I will win. return None # Frank is smiling for my all trials. He will win. # initialize m=5 d=[] for i in range(0,m): for j in range(0,m): d.append((i,j)) print "RESULT:", next(d)(引用元:Pythonによるプログラミング入門, p. 56)
なんか……長くない?
以下、(自分の理解できる範囲で)実際にプログラムが実行される順番に沿って見ていきます。結構複雑なので、順番が前後するところもありますが許して。
1行目 from copy import *
copy というモジュールを使います、という宣言。
21~28行目 # initialize
ここがプログラムの本体みたいな部分です。
- 22行目: m はマス目の縦横を意味します。
- 23: d は石を置くことのできるマス目を意味します。いまは空ですが、次でマス目データが入ります。
- 24~26: d にマス目データを入れています。ここで、マス目は (i, j) という座標で表されます( i, j には 0, 1, 2, 3, 4 のいずれかが入ります)。
- 28: 結果を表示します。next(d) という関数(後述)が勝つための手を計算してくれます。
7~9行目 def pr(d):
d の中で石を置くことができるマス目を p とし、それを表示します。
p は座標データなので、 (0, 1) とか、(4, 2) みたいな形です。
2~6行目 def put(d,p):
石を置いたとき、その場所と周囲1マスに石が置けなくなったことを教えてくれる関数です。
まず、石を置いた場所と、その周囲1マスをそれぞれ q という変数に入れます(q は p と同じく座標データです)。
そして、q がもしも d(マス目データ)に含まれているなら、 d からその座標を削除します。これでそのマス目には石が置けなくなった、ということになります。
例として、左上隅に石を置いた場合を考えましょう。
このとき、q に入るのは下の図の灰色になった9マスです。
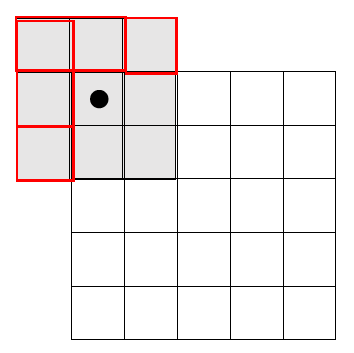
これらのうち、赤で囲まれたマスはそもそも存在しないため無視します。
一方で、残りの4マスはゲームの盤面内にあるため、これらは削除されます(石を置くことができなくなります)。
10~19行目 def next(d):
ラスボスです。ここでゲームに勝つための道筋が計算されます。
- 11行目: len(d) は d に値が残っているか、つまり、まだ石を置けるマスがあるかを確認し、ない場合には None を関数の計算結果とします。
- 12行目: 先ほどの関数 pr(d) を実行します。
- 13~18: 以下で詳しく見ます。
- 19: 13~18行目の for が終わっても有効な手が見つからない場合はここまで来ます。None を返す、つまりは投了ですね。
さて、13~18行目ですが、ここには前回勉強した再帰アルゴリズムが含まれます。これがなかなか理解しにくいです。
- 13行目: d に含まれるマスを一つ一つ見ていきますよ、という意味です。
- 14: いま見ているマスと、その後ろに「:」をプリントします。尻の「,」は、改行せずに続けてプリントしますよ、という意味です。
- 15: d のコピーを作って、それを変数 e に代入しています。これは for で石を置くパターンを変えていく際、それぞれのパターンを独立した状態に保つために必要な手順です。
- 16: e (いま作ったマス目データのコピー)内の p というマスに石を置きます。
- 17, 18: 再帰を使用しています。次に石を置くことができない場合、直前に石を置いたマス p が next(d) の結果として出力されます。
ざっとこんな感じですが、これを読んだだけではワケがわからないと思います。
参考までに、今回のプログラムで出力される結果を見てみましょう。
譜4.14 結果(最初の方だけ)
RESULT: (0, 0) (0, 1) (0, 2) (0, 3) (0, 4) (1, 0) (1, 1) (1, 2) (1, 3) (1, 4) (2, 0) (2, 1) (2, 2) (2, 3) (2, 4) (3, 0) (3, 1) (3, 2) (3, 3) (3, 4) (4, 0) (4, 1) (4, 2) (4, 3) (4, 4) (0, 0) : (0, 2) (0, 3) (0, 4) (1, 2) (1, 3) (1, 4) (2, 0) (2, 1) (2, 2) (2, 3) (2, 4) (3, 0) (3, 1) (3, 2) (3, 3) (3, 4) (4, 0) (4, 1) (4, 2) (4, 3) (4, 4) (0, 2) : (0, 4) (1, 4) (2, 0) (2, 1) (2, 2) (2, 3) (2, 4) (3, 0) (3, 1) (3, 2) (3, 3) (3, 4) (4, 0) (4, 1) (4, 2) (4, 3) (4, 4) (0, 4) : (2, 0) (2, 1) (2, 2) (2, 3) (2, 4) (3, 0) (3, 1) (3, 2) (3, 3) (3, 4) (4, 0) (4, 1) (4, 2) (4, 3) (4, 4) (以下略)
ますますワケがわからんといった感じですが、自分なりの解釈を説明しますね。
まず最初の RESULT: に続く座標たちは一つも石を置いていない状態でのマス目全体です。
次の (0,0): 以降は (0, 0) に石を置いたとき、次に石を置くことのできるマス目のリストです。
さらにその次、(0, 2): はいきなり (0, 1) を飛ばしているので困惑しますが、よく見るとこれは (0, 0) の次に石を置くことができるマス目リストのいちばん最初にある座標です。つまり、(0, 0) → (0, 2) と石を置いたとき、その次に石を置くことができるマス目のリストを示していることになります。
次の (0, 4): も同様です。(0, 0) → (0, 2) → (0, 4) と石を置いたとき、その次に石を置くことができるマス目のリストが表示されています。
こんな感じでどんどん石を置いていったときのパターンをずらーっと列挙してくれるのが今回のプログラムの仕様です。
ところで、これは自分でプログラムを回してみると確認できますが、結果の中には以下の3, 4行目ような形になっている部分も見られます。
譜4.14 結果(一部抜粋)
(4, 0) : (4, 2) (4, 3) (4, 4) (4, 2) : (4, 4) (4, 4) : (4, 3) : (4, 1) : (4, 3) (4, 4) (4, 3) : (4, 2) : (4, 0) (4, 4)
3行目は、for の途中で return によって無理矢理抜け出しているため、 14行目の print p,":", の最後の「,」が残っており、改行されないまま次のマスの結果を表示しているのだと思います。
具体的には以下のようになっているのかなぁと思います。
① … → (4, 0) → (4, 2) → (4, 4) と石を置いたけど、この次に置ける場所がない(None)
⇒ p = (4, 4) で、next(e) == None が成立
⇒ return p によって、ここでの結果を p とし、現在の再帰(for p in (4, 4))を途中で抜ける
⇒ 1つ前の再帰(p = (4, 2) / for p in (4, 2) (4, 3) (4, 4))に戻る
⇒ いま、結果は p になっているため、next(e) == None は成立しない(p = (4, 2) / for p in (4, 2) (4, 3) (4, 4) が終了)
⇒ for が進む(p = (4, 3) / for p in (4, 2) (4, 3) (4, 4))⇒ ②へ
② … → (4, 0) → (4, 3) と石を置いたけど、この次に置ける場所がない(None)
⇒ p = (4, 3) で、next(e) == None が成立
⇒ return p によって、ここでの結果を p とし、現在の再帰(for p in (4, 2) (4, 3) (4, 4))を途中で抜ける
⇒ 1つ前の再帰(p = (4, 0) / for p in (4, 0) (4, 1) (4, 2) (4, 3) (4, 4))に戻る
⇒ いま、結果は p になっているため、next(e) == None は成立しない(p = (4, 0) / for p in (4, 0) (4, 1) (4, 2) (4, 3) (4, 4) が終了)
⇒ for が進む(p = (4, 1) / for p in (4, 0) (4, 1) (4, 2) (4, 3) (4, 4))⇒ …
一応、図にしてみました。

長々書きましたが、言いたいことが十分に伝えられていない気がします。言語化するのは難しいなぁ。
今回はここまで!